LoRA: Low-Rank Adaptation for Efficient Fine-Tuning
A deep dive into low-rank parameter-efficient fine-tuning
The Fine-Tuning Landscape
In the era of large language models, adapting these models to downstream applications has become common practice through fine-tuning. While the focus of this post is LoRA, it's important to see where it falls in the bigger picture of fine-tuning approaches.
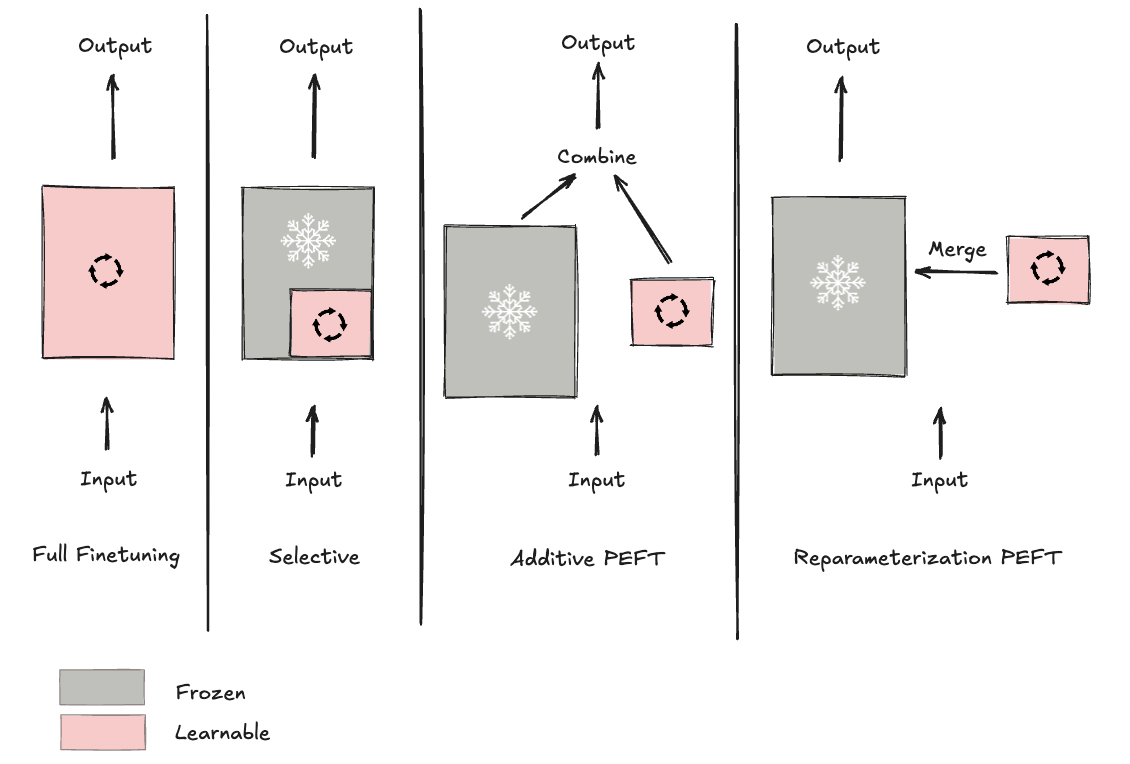
Full Fine-Tuning
When models were small enough (hundreds of thousands to a few million parameters), full fine-tuning was the standard approach. All parameters in the pretrained model would be updated during training. As model sizes grew to hundreds of billions and even trillions of parameters, this approach became prohibitively expensive in terms of compute, memory, and time, making it inaccessible to most practitioners.
Selective Fine-Tuning
A natural next step: freeze most layers and fine-tune only a subset. For instance, in a 10-layer model, you might freeze the first eight layers and fine-tune only the last two, reducing training to just 20% of the parameters. However, empirical results showed this approach was insufficient. Houlsby et al. (2019) found that for BERT-Large, you'd still need to fine-tune approximately 25% of the model to achieve performance comparable to full fine-tuning. With BERT-Large's 340 million parameters, that still means updating 85 million parameters. Fine-tuning just the top layers is inefficient and doesn't fully solve the compute and memory problem.
Additive Fine-Tuning
The question now becomes: How can we achieve near-full-fine-tuning performance while training orders of magnitude fewer parameters?
This motivated the development of parameter-efficient fine-tuning (PEFT) methods. Houlsby et al. (2019) introduced adapter layers- small trainable modules inserted into the frozen base model. In transformers, adapter modules are inserted after the self-attention and feed-forward sublayers. The adapter architecture consists of a down-projection (to reduce dimensionality), a non-linear activation function, and an up-projection (to restore dimensionality). Only these adapter parameters are trained.
This approach achieved performance within 0.4% of full fine-tuning while training only 3% of the model's parameters. However, adapter layers introduce a critical drawback: increased inference latency. Because of these additional layers, inference requires extra computation in each forward pass. This is problematic in production systems where low latency is crucial.
There's another class of additive techniques worth mentioning: soft prompting methods such as prefix tuning or prompt tuning. These modify how the model processes input rather than the architecture itself. We focus on adapters here because they lead most directly to LoRA.
It's also worth noting that PEFT methods are not only parameter-efficient but also sample-efficient, achieving strong performance with just a few thousand training examples, making them practical for low-resource settings.
Reparameterization Fine-Tuning
With trainable parameters successfully reduced by orders of magnitude, the next challenge was addressing the increased inference time.
Reparameterization methods introduce additional low-rank trainable parameters during training. The key difference from adapters: these parameters can be merged back into the original weights at inference time, preserving the base model's architecture. This results in no extra layers, no additional computation, no inference overhead.
The theoretical groundwork came from Aghajanyan et al. (2020), who showed in "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning" that common pretrained models have low intrinsic dimensionality. In other words, the weight updates needed during fine-tuning occupy a surprisingly low-dimensional subspace of the full parameter space. If the updates live in a small subspace, we don't need full-rank matrices to represent them.
This insight opened the door to LoRA and the family of reparameterization methods that followed, including variants like DyLoRA and DoRA. Our focus here remains on the original.
LoRA: Low-Rank Adaptation
Now that we've seen how reparameterization methods address the adapter latency problem, let's examine how LoRA specifically implements this approach.
Introduced by Hu et al. (2021), LoRA was originally applied to transformers but works on any architecture with learnable weight matrices.
For a pretrained weight matrix W₀ ∈ ℝm×n, we want to learn a matrix ΔW ∈ ℝm×n. Think of ΔW as incrementally updating the output to encapsulate task-specific knowledge:
$$W' = W_0 + \frac{\alpha}{r} \Delta W$$
Here's the key insight: weight updates during fine-tuning have low intrinsic rank. Even though W₀ is a large matrix, the task-specific changes (ΔW) lie in a much smaller subspace.
LoRA exploits this by decomposing ΔW into two low-rank matrices:
$$\Delta W = BA$$
Why Does Low-Rank Decomposition Work?
Pretrained models have already learned rich representations from massive datasets. Fine-tuning makes targeted adjustments along a small number of key directions. Think of it like learning Portuguese when you already speak Spanish: you adjust pronunciation, some vocabulary, and certain grammatical patterns while keeping most of your language knowledge intact. Similarly, fine-tuning adjusts pretrained weights along a low-dimensional subspace rather than requiring full-rank changes across all dimensions.
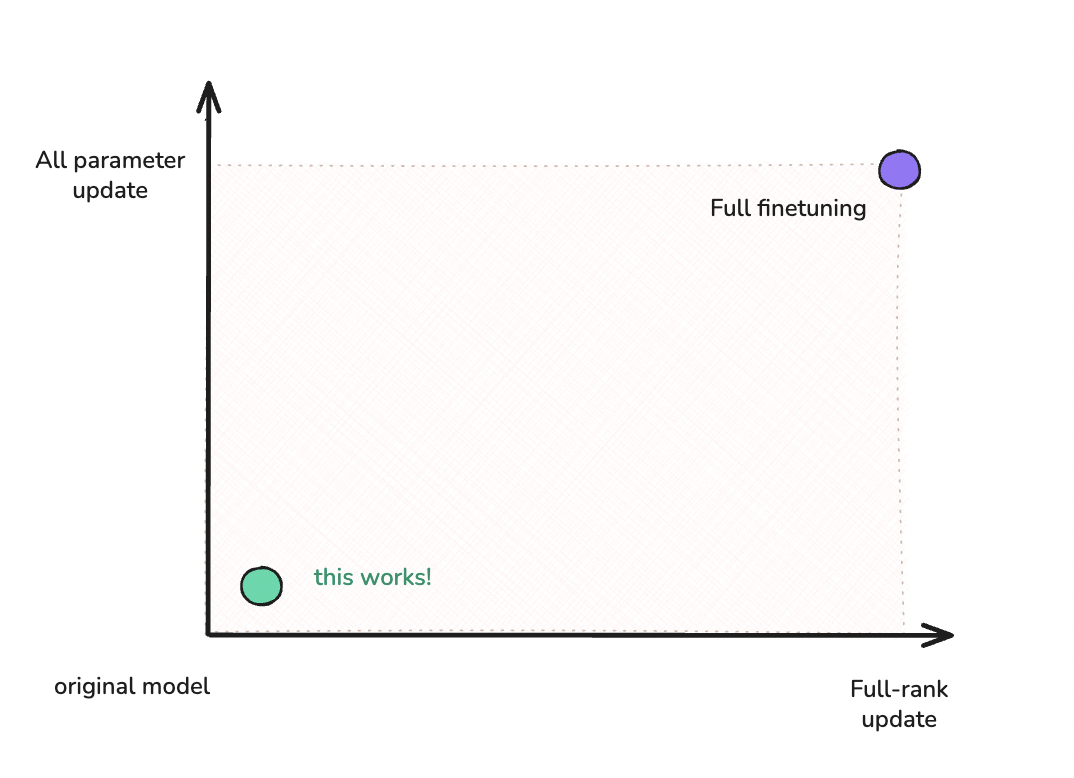
Empirically, the LoRA paper found that even r=1 or r=2 often suffice for effective adaptation on GPT-3, demonstrating that task-specific adaptation truly occupies a low-dimensional subspace.
The decomposition uses:
- B ∈ ℝm×r
- A ∈ ℝr×n
- r ≪ min(m,n) is the rank
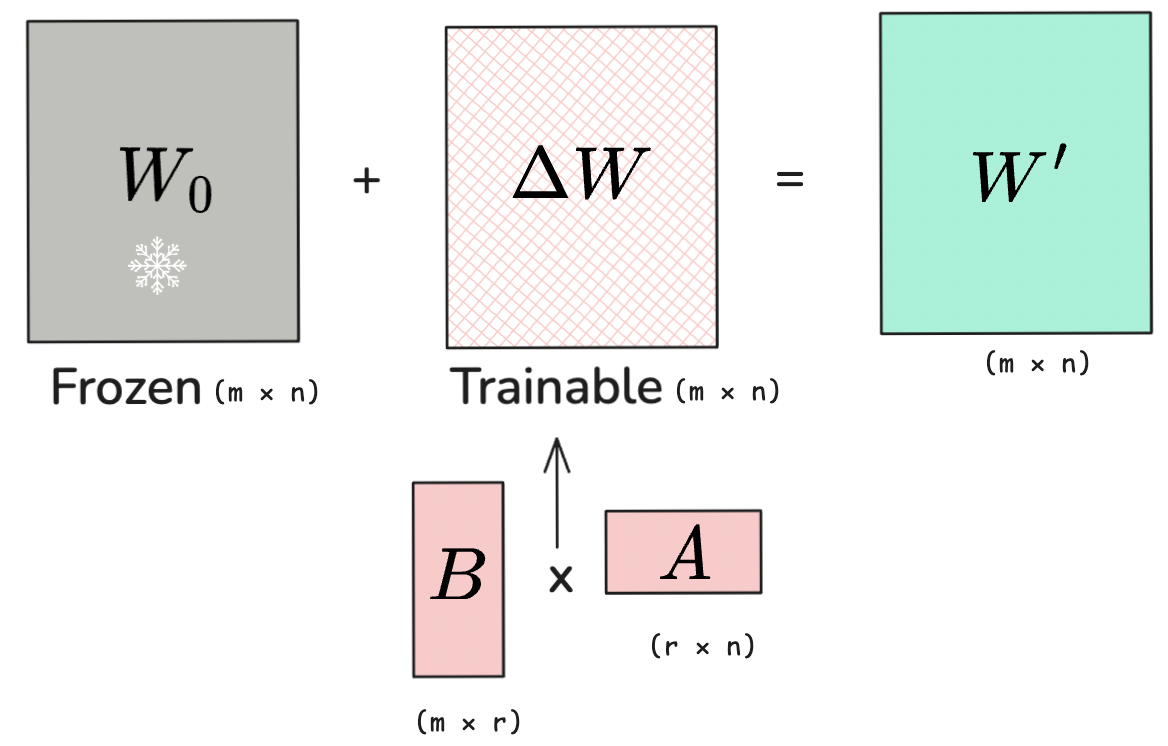
Instead of learning the full m×n matrix ΔW, we only train the smaller matrices B and A. This decomposition is what allows us to train such few parameters.
Let's look at a concrete example with a 768×768 weight matrix:
| Method | Calculation | Parameters | Reduction |
|---|---|---|---|
| Full ΔW (d=768) | 768 × 768 | 589,824 | — |
| LoRA (r=8) | (768 × 8) + (8 × 768) | 12,288 | 98% |
A 98% reduction in trainable parameters.
Initialization
Matrix A is initialized with random Gaussian values, while B is initialized to zero. This ensures that at the start of training, ΔW = BA = 0, so the model begins identical to its pretrained state. As training progresses, B learns to scale and combine the features from A.
Target Matrices in Transformers
LoRA is typically applied to the weight matrices in attention layers:
- WQ (query projection)
- WK (key projection)
- WV (value projection)
- WO (output projection)
The original paper found that applying LoRA to just WQ and WV gives the best performance-to-parameter tradeoff. You can extend to feed-forward layers (FFN) for improved performance at the cost of more trainable parameters, shown in our experiments below.
The Scaling Factor
The scaling factor α/r controls the magnitude of the update. A common heuristic is to set α = 2r, which keeps the effective learning rate stable across different ranks. In our experiments, we used this approach consistently.
Merging for Deployment
After training, the LoRA matrices are merged back into the original weights:
$$W_{merged} = W_0 + \frac{\alpha}{r}BA$$
This merged weight is the same dimension as the orignal weight matrix. Therefore, the model has identical architecture and speed to the base model, with zero computational overhead. This is LoRA's key advantage over adapter layers.
Practical Example: LoRA Fine-Tuning on IMDB
To see LoRA in action, I fine-tuned DistilBERT on the IMDB sentiment classification task using HuggingFace's PEFT library.
Setup
I used the full IMDB dataset: 25,000 training examples and 25,000 test examples, balanced 50/50 between positive and negative sentiment. All experiments ran on Google Colab Pro with an NVIDIA A100 GPU. Colab link below.
Configuration
Here's the core LoRA configuration setup on DistilBERT:
from peft import LoraConfig, get_peft_model, TaskType
# Configure LoRA
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # Sequence classification
r=8, # Rank of decomposition
lora_alpha=16, # Scaling factor (2*r)
lora_dropout=0.1, # Regularization
target_modules=["q_lin", "v_lin"], # Apply to Q and V matrices
bias="none",
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 739,586 || all params: 67,694,596 || trainable%: 1.10%
With just these few lines, we've converted a standard DistilBERT model (67M parameters) into one where only 740K parameters (1.10%) need to be trained. Above this shows training wth a rank of 8 on the Q and V matrices.
Experiments
I tested six configurations to understand the impact of rank and target module selection:
| Configuration | Trainable Params | Trainable % | Accuracy |
|---|---|---|---|
| Classification Head Only | 1,538 | 0.00% | 82.18% |
| Q+V (r=4) | 665,858 | 0.99% | 92.28% |
| Q+V (r=8) | 739,586 | 1.10% | 92.48% |
| Q+V (r=16) | 887,042 | 1.32% | 92.67% |
| All Attention (r=8) | 887,042 | 1.32% | 93.00% |
| All Attention+FFN (r=8) | 1,255,682 | 1.88% | 93.32% |
| Full Fine-Tuning | 66,955,010 | 100.00% | 93.26% |
All experiments on NVIDIA A100 GPU with full IMDB dataset (25K train, 25K test).
Key Findings
Rank shows diminishing returns:
- r=4: 92.28% accuracy with 666K parameters (0.99%)
- r=8: 92.48% accuracy with 740K parameters (1.10%)
- r=16: 92.67% accuracy with 887K parameters (1.32%)
Each doubling of rank provides smaller gains (~0.2% improvement), suggesting r=8 offers the best tradeoff for Q+V configurations.
Target module selection matters:
With similar parameter budgets (~887K), All Attention (r=8) achieved 93.00% compared to Q+V (r=16) at 92.67%. A 0.33% improvement from adding key and output projections.
Feed-forward layers provide the largest boost:
Extending LoRA to FFN layers (All Attention+FFN, r=8) achieved 93.32% accuracy. This slightly outperforms full fine-tuning's 93.26% while training only 1.88% of parameters. This represents a 98% reduction in trainable parameters with zero accuracy loss.
Classification head alone is insufficient:
Training only the classification head (1.5K parameters) achieved just 82.18% accuracy. Even the smallest LoRA configuration (Q+V r=4) dramatically outperformed this baseline with 10% higher accuracy.
The Sweet Spot
Based on our experiments and the LoRA paper:
- r=4: Very efficient, good for resource-constrained settings
- r=8: Sweet spot for most tasks, balances efficiency and performance
- r=16 or higher: Diminishing returns, use only if maximizing accuracy
For this classification task, Q+V with r=8 offers an excellent tradeoff: 92.48% accuracy with only 1.10% of parameters trainable. For applications requiring maximum performance, extending LoRA to feed-forward layers (All Attention+FFN with r=8) matches full fine-tuning while still using less than 2% of trainable parameters.
Implementation Notes
- Learning rate: LoRA worked well with a higher learning rate (3e-4) compared to full fine-tuning (2e-5)
- Training efficiency: All LoRA configurations trained in 3-6 minutes on an A100 GPU
- Merging: After training, the LoRA matrices can be merged back into the original weights for zero-overhead inference
The full training code, including data preprocessing and evaluation, is available in the notebook linked above.
Conclusion
LoRA demonstrates that effective fine-tuning doesn't require updating all model parameters. By exploiting the low intrinsic rank of weight updates, LoRA achieves near-full-fine-tuning performance while training less than 2% of parameters—with zero inference overhead. For practitioners working with large language models, LoRA has become the default fine-tuning approach, offering an optimal balance of efficiency, performance, and deployment simplicity.
References
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., ... & Gelly, S. (2019). Parameter-efficient transfer learning for NLP. International Conference on Machine Learning, 2790-2799.
Aghajanyan, A., Zettlemoyer, L., & Gupta, S. (2020). Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255.